3 Training and evaluating regression models
Machine learning models such as regression aim to predict the dependent variable, “y.” This chapter describes the machine learning processes to predict a time series. We will predict the ASURB.MX close price. As independent variables, we will use some macroeconomic variables.
ASURB.MX_pricet=β0+β1 ERt−1+β2 inflationt−1+β3 sratet−1+β4growtht−1+β5 mratet−1+β6 invt−1+β7 MRt−1+β8 SMAt−1+β9 MACDt−1+et Where ER is the exchange rate USD-MXN, inflation is the Mexican inflation, srate is the short term Mexican treasury bills (28 days), growth is the monthly Mexican economic growth indicator, mrate is the 1 year Mexican treasury bills, invis the Mexican gross fixed investment, MR is the Mexican stock market index, SMAt−1 is smooth moving average, MACDt−1 is the Moving Average Convergence Divergence (MACD) indicator and e is the error term.
3.1 Data collection and cleaning.
In this section, we use the APIs we cover in Chapter 1. Also, we will use other sources of information. In some cases, we will detect and clean missing values. First we download the yahoo finance information.
import numpy as np
import pandas as pd
import yfinance as yf
from sie_banxico import SIEBanxico
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt# This function download market data from Yahoo! Finance's
# It returns a data frame with a specific format date.
# Parameters:
# tickers: a list with the Yahoo Finance ticker symbol
# inter: intervals: 1m,2m,5m,15m,30m,60m,90m,1h,1d,5d,1wk,1mo,3mo
# price_type: Open', 'High', 'Low', 'Close', 'Volume', 'Dividends', 'Stock Splits
# format_date: index format date
# d_ini: initial date if the subset
# d_fin: final date of the subset
def my_yahoo_tickers(tickers,inter,price_type,format_date,d_ini,d_fin):
def my_yahoo(ticker,inter,price_type,format_date,d_ini,d_fin):
x = yf.Ticker(ticker)
hist = x.history(start=d_ini,end=d_fin,interval=inter)
date=list(hist.index)
hist_date=[date.strftime(format_date) for date in date]
price=list(hist[price_type])
hist={ticker:price}
hist=pd.DataFrame(hist,index=hist_date)
return hist.loc[d_ini:d_fin]
if len(tickers)==1:
s1=my_yahoo(tickers[0],inter,price_type,format_date,d_ini,d_fin)
else:
s1=my_yahoo(tickers[0],inter,price_type,format_date,d_ini,d_fin)
for ticker in range(1,len(tickers)):
s2=my_yahoo(tickers[ticker],inter,price_type,format_date,d_ini,d_fin)
s1=pd.concat([s1,s2],axis=1)
return s1
inter='1mo'
price_type="Close"
format_date="%Y-%m-%d"
d_ini="2020-06-01"
d_fin="2023-04-01"
tickers = ["ASURB.MX","^MXX"]df=my_yahoo_tickers(tickers,inter,price_type,format_date,d_ini,d_fin)
df.head()| ASURB.MX | ^MXX | |
|---|---|---|
| 2020-06-01 | 235.398758 | 37716.429688 |
| 2020-07-01 | 202.884109 | 37019.679688 |
| 2020-08-01 | 227.446655 | 36840.730469 |
| 2020-09-01 | 235.527176 | 37458.691406 |
| 2020-10-01 | 224.731766 | 36987.859375 |
Also, we download the macroeconomic variables using the Banxico API we used in chapter 1.
| TC | Cetes_28 | infla | igae | Cetes_1a | inv_fija | |
|---|---|---|---|---|---|---|
| 2020-06-01 | 22.299000 | 5.060000 | 0.370000 | 97.955100 | 4.910000 | 78.690000 |
| 2020-07-01 | 22.403300 | 4.820000 | 0.400000 | 102.421600 | 4.610000 | 80.340000 |
| 2020-08-01 | 22.207200 | 4.490000 | 0.320000 | 102.838300 | 4.480000 | 85.850000 |
| 2020-09-01 | 21.681000 | 4.380000 | 0.320000 | 103.512100 | 4.450000 | 85.640000 |
| 2020-10-01 | 21.270500 | 4.200000 | 0.240000 | 109.458500 | 4.370000 | 88.400000 |
#---- Do not change anything from here ----
def my_banxico_py(token,my_series,my_series_name,d_in,d_fin,format_date):
le=len(my_series)
ser=0
if(le==1):
ser=0
api = SIEBanxico(token = token, id_series = my_series[ser])
timeseries_range=api.get_timeseries_range(init_date=d_in, end_date=d_fin)
timeseries_range=timeseries_range['bmx']['series'][0]['datos']
data=pd.DataFrame(timeseries_range)
dates=[pd.Timestamp(date).strftime(format_date) for date in list(data["fecha"])]
data=pd.DataFrame({my_series_name[ser]:list(data["dato"])},index=dates)
else:
ser=0
api = SIEBanxico(token = token, id_series = my_series[ser])
timeseries_range=api.get_timeseries_range(init_date=d_in, end_date=d_fin)
timeseries_range=timeseries_range['bmx']['series'][0]['datos']
data=pd.DataFrame(timeseries_range)
dates=[pd.Timestamp(date).strftime(format_date) for date in list(data["fecha"])]
data=pd.DataFrame({my_series_name[ser]:list(data["dato"])},index=dates)
for ser in range(1,le):
api = SIEBanxico(token = token, id_series = my_series[ser])
timeseries_range=api.get_timeseries_range(init_date=d_in, end_date=d_fin)
timeseries_range=timeseries_range['bmx']['series'][0]['datos']
data2=pd.DataFrame(timeseries_range)
dates2=[pd.Timestamp(date).strftime(format_date) for date in list(data2["fecha"])]
data2=pd.DataFrame({my_series_name[ser]:list(data2["dato"])},index=dates2)
data=pd.concat([data,data2],axis=1)
ban_names=list(data.columns)
for col_i in range(data.shape[1]):
cel_num=[float(cel) for cel in data[ban_names[col_i]]]
data[ban_names[col_i]]=cel_num
return data
#----- To here ------------
token = "776cab8e243c5b661cee8571d7e3e5d573395471011cf093ab5684d233a80d67"
my_series=['SF17908' ,'SF282',"SP74660","SR16734","SF3367","SR16525"]
my_series_name=["TC","Cetes_28","infla","igae","Cetes_1a","inv_fija"]
d_ini="2020-02-01"
d_fin="2023-02-01"
format_date="%Y-%d-%m"
ban=my_banxico_py(token,my_series,my_series_name,d_ini,d_fin,format_date)
ban.head()Here we concatenate the Banxico data and the Yahoo Finance one.
dataset=pd.concat([ban,yf],axis=1)
dataset.head()| TC | Cetes_28 | infla | igae | Cetes_1a | inv_fija | ASURB.MX | ^MXX | |
|---|---|---|---|---|---|---|---|---|
| 2020-06-01 | 22.299000 | 5.060000 | 0.370000 | 97.955100 | 4.910000 | 78.690000 | 235.398758 | 37716.429688 |
| 2020-07-01 | 22.403300 | 4.820000 | 0.400000 | 102.421600 | 4.610000 | 80.340000 | 202.884109 | 37019.679688 |
| 2020-08-01 | 22.207200 | 4.490000 | 0.320000 | 102.838300 | 4.480000 | 85.850000 | 227.446655 | 36840.730469 |
| 2020-09-01 | 21.681000 | 4.380000 | 0.320000 | 103.512100 | 4.450000 | 85.640000 | 235.527176 | 37458.691406 |
| 2020-10-01 | 21.270500 | 4.200000 | 0.240000 | 109.458500 | 4.370000 | 88.400000 | 224.731766 | 36987.859375 |
The next function is to generate smooth moving average variables:
# This function creates moving average variables SMAs
# It returns a data frame with the SMAs.
# Parameters:
# data: Data fame with the variables
# n: initial SMA
# m: final SMA
# col: column name of the variable we want to create the SMA´s
def lag_gen(data,n,m,col):
data_c=data.copy()
data_c['SMA'+str(n)] = data_c[col].rolling(n).mean()
for n in range(n+1,m+1):
data_c['SMA'+str(n)] = data_c[col].rolling(n).mean()
return data_c.iloc[m-1:,]
n=2
m=3
data_sme=lag_gen(dataset,n,m,"ASURB.MX")
data_sme.head()
#> TC Cetes_28 infla ... ^MXX SMA2 SMA3
#> 2020-08-01 22.2072 4.49 0.32 ... 36840.730469 215.165382 221.909841
#> 2020-09-01 21.6810 4.38 0.32 ... 37458.691406 231.486916 221.952647
#> 2020-10-01 21.2705 4.20 0.24 ... 36987.859375 230.129471 229.235199
#> 2020-11-01 20.3819 4.23 -0.08 ... 41778.871094 250.271126 245.356476
#> 2020-12-01 19.9651 4.27 0.55 ... 44066.878906 288.885147 267.500687
#>
#> [5 rows x 10 columns]Finally, we create the MACD indicators:
# This function the MACD indicator.
# It returns a data frame with the MACD indicator and its signal.
# Parameters:
# df: Data fame containing the variable we want to create the MACD
# col: colum name of the variable we want to create the MACD
# n_fast: fast SMA
# n_slow: slow SMA
# signal: signal SMA
def computeMACD (data, col,n_fast, n_slow, signal):
fastEMA = data[col].ewm(span=n_fast, min_periods=n_slow).mean()
slowEMA = data[col].ewm(span=n_slow, min_periods=n_slow).mean()
MACD = pd.Series(fastEMA-slowEMA, name = 'MACD')
MACDsig = pd.Series(MACD.ewm(span=signal, min_periods=signal).mean(), name='MACDsig')
data1 = data[[col]].join(MACD)
data1 = data1.join(MACDsig)
return data1.iloc[signal:,1:]
fast=4
slow=2
signal=1
macd=computeMACD(dataset,"ASURB.MX", fast, slow, signal)
macd=macd.iloc[signal:,]
macd.head()
#> MACD MACDsig
#> 2020-08-01 -1.001977 -1.001977
#> 2020-09-01 -3.371782 -3.371782
#> 2020-10-01 -0.371240 -0.371240
#> 2020-11-01 -12.348315 -12.348315
#> 2020-12-01 -18.100869 -18.100869We concatenate the object “data_sme” with the macd. In this case, we add the argument: join=“inner” to avoid having more observations of the macd objec.
dataset=pd.concat([data_sme,macd],axis=1,join="inner")
dataset.head()
#> TC Cetes_28 infla ... SMA3 MACD MACDsig
#> 2020-08-01 22.2072 4.49 0.32 ... 221.909841 -1.001977 -1.001977
#> 2020-09-01 21.6810 4.38 0.32 ... 221.952647 -3.371782 -3.371782
#> 2020-10-01 21.2705 4.20 0.24 ... 229.235199 -0.371240 -0.371240
#> 2020-11-01 20.3819 4.23 -0.08 ... 245.356476 -12.348315 -12.348315
#> 2020-12-01 19.9651 4.27 0.55 ... 267.500687 -18.100869 -18.100869
#>
#> [5 rows x 12 columns]dataset.tail()
#> TC Cetes_28 infla ... SMA3 MACD MACDsig
#> 2022-11-01 19.4449 9.42 0.45 ... 437.777802 -18.206929 -18.206929
#> 2022-12-01 19.5930 9.96 0.65 ... 456.737162 -7.524922 -7.524922
#> 2023-01-01 18.9863 10.61 0.71 ... 471.529449 -18.081344 -18.081344
#> 2023-02-01 18.5986 10.92 0.61 ... 486.354401 -18.934665 -18.934665
#> 2023-03-01 18.3749 11.23 0.52 ... 518.118927 -21.204506 -21.204506
#>
#> [5 rows x 12 columns]3.1.1 Definition of the independent variable
Here we define the independent variable and do some tests.
As we mention below, we want to predict the rticker` price in one month. Then, our model state that we have to lag one period, one month in this case, the dependent variable
ASURB.MX_pricet. Remember that our model is:
ASURB.MX_pricet=β0+β1 ERt−1+β2 inflationt−1+β3 sratet−1+β4growtht−1+β5 mratet−1+β6 invt−1+β7 MRt−1+β8 SMAt−1+β9 MACDt−1+et Where the suffix t−1 indicates the variable one period before period t.
To automate the procedure, we define:
var="ASURB.MX" # name of the ticker we want to predict
lag=-1 # number of periods we want to lagWe use the function shift():
y_lag=dataset[var].shift(lag)
y_lag.head()#> 2020-08-01 235.527176
#> 2020-09-01 224.731766
#> 2020-10-01 275.810486
#> 2020-11-01 301.959808
#> 2020-12-01 295.823730
#> Name: ASURB.MX, dtype: float64Then we insert the lagged variable in the data set, adding the text “_lag”:
dataset[var+"_lag"]= y_lag
dataset.head() #| TC | Cetes_28 | infla | igae | Cetes_1a | inv_fija | ASURB.MX | ^MXX | SMA2 | SMA3 | MACD | MACDsig | ASURB.MX_lag | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2020-08-01 | 22.207200 | 4.490000 | 0.320000 | 102.838300 | 4.480000 | 85.850000 | 227.446655 | 36840.730469 | 215.165382 | 221.909841 | -1.001977 | -1.001977 | 235.527176 |
| 2020-09-01 | 21.681000 | 4.380000 | 0.320000 | 103.512100 | 4.450000 | 85.640000 | 235.527176 | 37458.691406 | 231.486916 | 221.952647 | -3.371782 | -3.371782 | 224.731766 |
| 2020-10-01 | 21.270500 | 4.200000 | 0.240000 | 109.458500 | 4.370000 | 88.400000 | 224.731766 | 36987.859375 | 230.129471 | 229.235199 | -0.371240 | -0.371240 | 275.810486 |
| 2020-11-01 | 20.381900 | 4.230000 | -0.080000 | 111.325800 | 4.360000 | 89.880000 | 275.810486 | 41778.871094 | 250.271126 | 245.356476 | -12.348315 | -12.348315 | 301.959808 |
| 2020-12-01 | 19.965100 | 4.270000 | 0.550000 | 111.193100 | 4.320000 | 90.710000 | 301.959808 | 44066.878906 | 288.885147 | 267.500687 | -18.100869 | -18.100869 | 295.823730 |
As we see, the last row has a missing value, the one we lost by doing the lag.
dataset.tail()| TC | Cetes_28 | infla | igae | Cetes_1a | inv_fija | ASURB.MX | ^MXX | SMA2 | SMA3 | MACD | MACDsig | ASURB.MX_lag | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2022-11-01 | 19.444900 | 9.420000 | 0.450000 | 116.235500 | 10.840000 | 103.440000 | 469.163208 | 51684.859375 | 462.530212 | 437.777802 | -18.206929 | -18.206929 | 445.151062 |
| 2022-12-01 | 19.593000 | 9.960000 | 0.650000 | 115.657400 | 10.870000 | 107.190000 | 445.151062 | 48463.859375 | 457.157135 | 456.737162 | -7.524922 | -7.524922 | 500.274078 |
| 2023-01-01 | 18.986300 | 10.610000 | 0.710000 | 112.099500 | 11.090000 | 106.030000 | 500.274078 | 54564.269531 | 472.712570 | 471.529449 | -18.081344 | -18.081344 | 513.638062 |
| 2023-02-01 | 18.598600 | 10.920000 | 0.610000 | 109.550400 | 11.660000 | 105.420000 | 513.638062 | 52758.058594 | 506.956070 | 486.354401 | -18.934665 | -18.934665 | 540.444641 |
| 2023-03-01 | 18.374900 | 11.230000 | 0.520000 | 115.293800 | 11.880000 | nan | 540.444641 | 53904.000000 | 527.041351 | 518.118927 | -21.204506 | -21.204506 | nan |
That missing value would´t allow us to perform some procedures below. Then we cut it, using the method shape, which shows the number of rows and columns of a data frame.
in this case the data set has 32 rows and 13 columns.
dataset_lag=dataset.iloc[:dataset.shape[0]-1,]
dataset_lag.head()| TC | Cetes_28 | infla | igae | Cetes_1a | inv_fija | ASURB.MX | ^MXX | SMA2 | SMA3 | MACD | MACDsig | ASURB.MX_lag | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2020-08-01 | 22.207200 | 4.490000 | 0.320000 | 102.838300 | 4.480000 | 85.850000 | 227.446655 | 36840.730469 | 215.165382 | 221.909841 | -1.001977 | -1.001977 | 235.527176 |
| 2020-09-01 | 21.681000 | 4.380000 | 0.320000 | 103.512100 | 4.450000 | 85.640000 | 235.527176 | 37458.691406 | 231.486916 | 221.952647 | -3.371782 | -3.371782 | 224.731766 |
| 2020-10-01 | 21.270500 | 4.200000 | 0.240000 | 109.458500 | 4.370000 | 88.400000 | 224.731766 | 36987.859375 | 230.129471 | 229.235199 | -0.371240 | -0.371240 | 275.810486 |
| 2020-11-01 | 20.381900 | 4.230000 | -0.080000 | 111.325800 | 4.360000 | 89.880000 | 275.810486 | 41778.871094 | 250.271126 | 245.356476 | -12.348315 | -12.348315 | 301.959808 |
| 2020-12-01 | 19.965100 | 4.270000 | 0.550000 | 111.193100 | 4.320000 | 90.710000 | 301.959808 | 44066.878906 | 288.885147 | 267.500687 | -18.100869 | -18.100869 | 295.823730 |
Here we define the dependent variable (Y):
Y=dataset_lag[var+"_lag"] # esto es el resultado, pero quiero automatizarlo
Y.head()
#> 2020-08-01 235.527176
#> 2020-09-01 224.731766
#> 2020-10-01 275.810486
#> 2020-11-01 301.959808
#> 2020-12-01 295.823730
#> Name: ASURB.MX_lag, dtype: float643.1.2 Testing for stationary in the dependet variable (Y)
A stationary time series process is one whose probability distributions are stable over time in the following sense: If we take any collection of random variables in the sequence and then shift that sequence ahead h time periods, the joint probability distribution must remain unchanged.
On a practical level, if we want to understand the relationship between two or more variables using regression analysis, such as the model:
ASURB.MX_pricet=β0+β1 ERt−1+β2 inflationt−1+..+et,
we need to assume some sort of stability over time. If we allow the relationship between two variables those variables in the equation to change arbitrarily in each time period, then we cannot hope to learn much about how a change in one variable affects the other variable if we only have access to a single time series realization (Wooldridge 2020). In the Appendix we extend this explanation.
Because this is an introductory machine learning book, we only would apply the Augmented Dickey-Fuller (ADF) (see (Wooldridge 2020) for a further reading).
# This method shows the ADF statistic and P-value
# Parameters:
# data: is a data frame of time Pandas Series with the time serie
#---- Do not change anything from here ----
from statsmodels.tsa.stattools import adfuller
def adf(data):
ADF = adfuller(data)
return print(f'ADF Statistic: {ADF[0]}',f'p-value: {ADF[1]}')
#----- To here ------------
adf(Y)
#> ADF Statistic: -0.7321673782995486 p-value: 0.838240618032143If the second term of the output, the P-value, is less than 10% (0.1), then we can perform the prediction with that time series. If it is greater than 10%(0.1), we have to adjust, such as the change of the variable.
in this case, the P-value is less than 10%(0.1), then the time series is not stationary, then we have to do an adjustment. The adjustment we will do is to do the change in the independent varible:
ΔASURB.MX_pricet=β0+β1 ERt−1+β2 inflationt−1+..+et, The ΔASURB.MX means the change in the variable, ASURB.MX_pricet−ASURB.MX_pricet−1. To do that we use the method diff. First we need to do a copy of the dataset_lag, other wise we could get a warning about the method.
dataset_lag_dif=dataset_lag.copy()
dataset_lag_dif[var+"_lag_dif"]=Y.diff()
dataset_lag_dif.head()| TC | Cetes_28 | infla | igae | Cetes_1a | inv_fija | ASURB.MX | ^MXX | SMA2 | SMA3 | MACD | MACDsig | ASURB.MX_lag | ASURB.MX_lag_dif | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2020-08-01 | 22.207200 | 4.490000 | 0.320000 | 102.838300 | 4.480000 | 85.850000 | 227.446655 | 36840.730469 | 215.165382 | 221.909841 | -1.001977 | -1.001977 | 235.527176 | nan |
| 2020-09-01 | 21.681000 | 4.380000 | 0.320000 | 103.512100 | 4.450000 | 85.640000 | 235.527176 | 37458.691406 | 231.486916 | 221.952647 | -3.371782 | -3.371782 | 224.731766 | -10.795410 |
| 2020-10-01 | 21.270500 | 4.200000 | 0.240000 | 109.458500 | 4.370000 | 88.400000 | 224.731766 | 36987.859375 | 230.129471 | 229.235199 | -0.371240 | -0.371240 | 275.810486 | 51.078720 |
| 2020-11-01 | 20.381900 | 4.230000 | -0.080000 | 111.325800 | 4.360000 | 89.880000 | 275.810486 | 41778.871094 | 250.271126 | 245.356476 | -12.348315 | -12.348315 | 301.959808 | 26.149323 |
| 2020-12-01 | 19.965100 | 4.270000 | 0.550000 | 111.193100 | 4.320000 | 90.710000 | 301.959808 | 44066.878906 | 288.885147 | 267.500687 | -18.100869 | -18.100869 | 295.823730 | -6.136078 |
As we see the lost one observation at the begining, then we cut that row.
dataset_lag_dif=dataset_lag_dif.iloc[1:,]
dataset_lag_dif.head()| TC | Cetes_28 | infla | igae | Cetes_1a | inv_fija | ASURB.MX | ^MXX | SMA2 | SMA3 | MACD | MACDsig | ASURB.MX_lag | ASURB.MX_lag_dif | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2020-09-01 | 21.681000 | 4.380000 | 0.320000 | 103.512100 | 4.450000 | 85.640000 | 235.527176 | 37458.691406 | 231.486916 | 221.952647 | -3.371782 | -3.371782 | 224.731766 | -10.795410 |
| 2020-10-01 | 21.270500 | 4.200000 | 0.240000 | 109.458500 | 4.370000 | 88.400000 | 224.731766 | 36987.859375 | 230.129471 | 229.235199 | -0.371240 | -0.371240 | 275.810486 | 51.078720 |
| 2020-11-01 | 20.381900 | 4.230000 | -0.080000 | 111.325800 | 4.360000 | 89.880000 | 275.810486 | 41778.871094 | 250.271126 | 245.356476 | -12.348315 | -12.348315 | 301.959808 | 26.149323 |
| 2020-12-01 | 19.965100 | 4.270000 | 0.550000 | 111.193100 | 4.320000 | 90.710000 | 301.959808 | 44066.878906 | 288.885147 | 267.500687 | -18.100869 | -18.100869 | 295.823730 | -6.136078 |
| 2021-01-01 | 19.921500 | 4.220000 | 0.360000 | 105.545700 | 4.220000 | 90.370000 | 295.823730 | 42985.730469 | 298.891769 | 291.198008 | -12.813249 | -12.813249 | 359.018616 | 63.194885 |
Again we define the Y variable:
Y=dataset_lag_dif[var+"_lag_dif"]
Y.head()
#> 2020-09-01 -10.795410
#> 2020-10-01 51.078720
#> 2020-11-01 26.149323
#> 2020-12-01 -6.136078
#> 2021-01-01 63.194885
#> Name: ASURB.MX_lag_dif, dtype: float64Now we make a subset to get the independent variables (X´s):
X=dataset_lag_dif.drop(columns=[var,var+"_lag",var+"_lag_dif"],axis=1)
X.head()
#> TC Cetes_28 infla ... SMA3 MACD MACDsig
#> 2020-09-01 21.6810 4.38 0.32 ... 221.952647 -3.371782 -3.371782
#> 2020-10-01 21.2705 4.20 0.24 ... 229.235199 -0.371240 -0.371240
#> 2020-11-01 20.3819 4.23 -0.08 ... 245.356476 -12.348315 -12.348315
#> 2020-12-01 19.9651 4.27 0.55 ... 267.500687 -18.100869 -18.100869
#> 2021-01-01 19.9215 4.22 0.36 ... 291.198008 -12.813249 -12.813249
#>
#> [5 rows x 11 columns]3.2 Training and test set (Back testing)
In the machine learning literature is common to apply that testing procedure for several observations. We call this back-testing, which divides the data set into training and testing, often called in_sample and out_sample.
To answer why we need a back-testing, think that if we want to validate the prediction performance, we have at least two alternatives:
Alternative 1: Estimate a ML model, make a prediction and wait in time, for example, 30 days, to verify if the prediction is good or not; if the forecast is not good (it is not close to the real value), then we have to train and test it again, let’s say other 30 days and so on.
Alternative 2 (The one we will apply): Take aside some observations, assuming those are observations we don’t know and store them in a data frame called “test.” Train and test the ML model. If we are not making a good prediction, we train and test the model again until we get a good prediction performance.
validation_size = 0.2
#In case the data is not dependent on the time series, then train and test split randomly
# seed = 7
# X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=validation_size, random_state=seed)
#In case the data is not dependent on the time series, then train and test split should be done based on sequential sample
#This can be done by selecting an arbitrary split point in the ordered list of observations and creating two new datasets.
train_size = int(len(X) * (1-validation_size))
X_train, X_test = X[0:train_size], X[train_size:len(X)]
Y_train, Y_test = Y[0:train_size], Y[train_size:len(X)]We start by running the Linear regression model, one of several machine learning models.
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, Y_train)LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
Apparently, we did not get a result. But in the model object we store some information, such as the coefficients of the model:
ASURB.MX_pricet=β0+β1 ERt−1+β2 inflationt−1+β3 sratet−1+β4 growtht−1+β5 mratet−1+β6 invt−1+β7 MRt−1+et
We do the prediction of the ASURB.MX price, in the X_test data set:
y_pred=model.predict(X_test)
y_pred
#> array([ 14.47731332, -15.05378659, 6.84411905, 17.04899556,
#> 18.88154119, 25.479381 ])3.2.1 Performance Measure Root Mean Square Error (RMSE).
In the previous section, we discussed whether the prediction was good (the prediction performance). This section formally defines the metrics for the prediction performance.
The first metric is the Root Mean Square Error (RMSE). The mathematical formula to compute the RMSE is:
RMSE=√1n n∑i=1(yi−^yi)2
where ^yi is the prediction for the ith observation, yi is the ith observation of the independent variable we store in the test set, and n is the number of observations.
^yi=^β0+^β1x1+,..,+^βnxn
We can estimate the RMSE using the training data set. But generally, we do not care how well the model works on the training set. Rather, we are interested in the model performance tested on unseen data; then, we try the RMSE on the test data set or the validation set for cross-validation. The lower the test RMSE, the better the prediction.
3.2.2 Mean absolute error (MAE)
from sklearn.metrics import mean_squared_error
import math
mse=mean_squared_error(Y_test, y_pred)
rmse=math.sqrt(mse)
rmse
#> 31.781940294101783The RMSE is generally the preferred performance measure for regression models. However, measuring the model performance with the MAE is useful when the data has some outliers.
MAE=1n n∑i=1|yi−^yi|
In our example, the Mean absolute error test (MAE) is:
mean_squared_error(Y_test, y_pred)
#> 1010.09172885785063.3 Several models
In the next sections, we aim to improve the prediction performance by minimizing the RMSE. We will look for another machine learning model, besides LinearRegression(), that can help us improve the RMSE. The following code was taken from (Hariom Tatsat and Lookabaugh 2021). Which is a very good book for machine learning in finance.
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.linear_model import BayesianRidge
from sklearn.linear_model import TweedieRegressormodels = []
models.append(('LR', LinearRegression()))
models.append(('LASSO', Lasso()))
models.append(('Ridge', Ridge()))
models.append(('EN', ElasticNet()))
models.append(('CART', DecisionTreeRegressor()))
models.append(('KNN', KNeighborsRegressor()))
models.append(('SVR', SVR()))
models.append(('RFR', RandomForestRegressor()))
models.append(('GBR', GradientBoostingRegressor()))
models.append(('ETR', ExtraTreesRegressor()))
models.append(('ABR', AdaBoostRegressor()))
models.append(('BayRidge', BayesianRidge()))
models.append(('Tweedie', TweedieRegressor()))
# Bagging methods
models
#> [('LR', LinearRegression()), ('LASSO', Lasso()), ('Ridge', Ridge()), ('EN', ElasticNet()), ('CART', DecisionTreeRegressor()), ('KNN', KNeighborsRegressor()), ('SVR', SVR()), ('RFR', RandomForestRegressor()), ('GBR', GradientBoostingRegressor()), ('ETR', ExtraTreesRegressor()), ('ABR', AdaBoostRegressor()), ('BayRidge', BayesianRidge()), ('Tweedie', TweedieRegressor())]names = []
test_results = []
train_results = []
for name, model in models:
names.append(name)
res = model.fit(X_train, Y_train)
train_result = mean_squared_error(res.predict(X_train), Y_train)
train_results.append(train_result)
# Test results
test_result = mean_squared_error(res.predict(X_test), Y_test)
test_results.append(test_result)
#> C:\Users\L01413~1\AppData\Local\MINICO~1\lib\site-packages\sklearn\linear_model\_glm\glm.py:284: ConvergenceWarning: lbfgs failed to converge (status=1):
#> STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
#>
#> Increase the number of iterations (max_iter) or scale the data as shown in:
#> https://scikit-learn.org/stable/modules/preprocessing.html
#> self.n_iter_ = _check_optimize_result("lbfgs", opt_res)from matplotlib import pyplot
fig = pyplot.figure()
ind = np.arange(len(names)) # the x locations for the groups
width = 0.35 # the width of the bars
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.bar(ind - width/2, train_results, width=width, label='Train Error')
#> <BarContainer object of 13 artists>
pyplot.bar(ind + width/2, test_results, width=width, label='Test Error')
#> <BarContainer object of 13 artists>
fig.set_size_inches(15,8)
pyplot.legend()
ax.set_xticks(ind)
ax.set_xticklabels(names)
pyplot.show()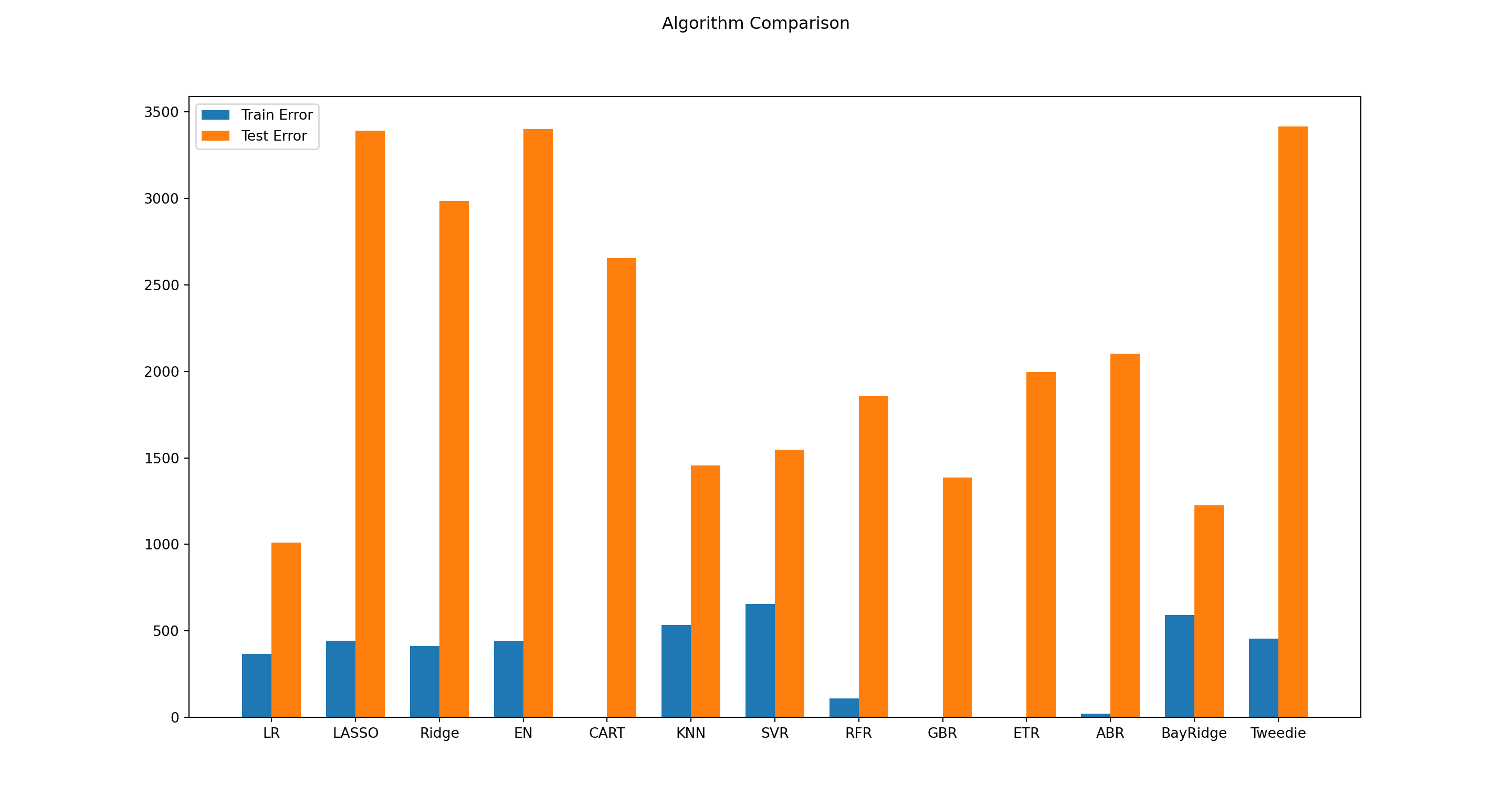
res=pd.DataFrame({"names": names,"res":test_results}).sort_values('res', ascending=True)
best=res["names"].iloc[0:1,].tolist()[0]
model_1=dict(models)[best]
model_1LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
def my_forward(X,Y,model):
def model_step(x,y,model1):
validation_size = 0.2
train_size = int(len(x) * (1-validation_size))
x_train, x_test = x[0:train_size], x[train_size:len(x)]
y_train, y_test = y[0:train_size], y[train_size:len(x)]
model = model1
model.fit(x_train, y_train)
y_pred=model.predict(x_test)
return mean_squared_error(y_test, y_pred)
rmse_f=[]
names_d={}
n=2
for col in range(1,X.shape[1]):
x=X.iloc[:,0:col]
rmse_f.append(model_step(x,Y,model))
names_d[model_step(x,Y,model)]=x.columns.tolist()
res2=pd.DataFrame(list(names_d.keys()),columns=["rmse"]).sort_values('rmse', ascending=True)
res3=names_d[res2.iloc[0,].tolist()[0]]
rmse=round(res2.iloc[0,].tolist()[0],8)
print(f'Best RMSE: {rmse}',f'vars: {res3}')
my_forward(X,Y,model_1)
#> Best RMSE: 1010.09172886 vars: ['TC', 'Cetes_28', 'infla', 'igae', 'Cetes_1a', 'inv_fija', '^MXX', 'SMA2', 'SMA3', 'MACD']3.4 Appendix
3.4.1 Stationary and Nonstationary Time Series
Historically, the notion of a stationary process has played an important role in the analysis of time series. A stationary time series process is one whose probability distributions are stable over time in the following sense: If we take any collection of random variables in the sequence and then shift that sequence ahead h time periods, the joint probability distribution must remain unchanged.
The stochastic process $x_{t}: t=1,2,…, $ is stationary if for every collection of time indices 1≤t1<t2<…<tm, the joint distribution of (xt1,xt2,…,xtm) is the same as the joint distribution of (xt1+h=xt2+h,...,xtn+h) for all integers h≥1.
Covariance Stationary Process. A stochastic process xt:t=1,2,… with a finite second moment E(x2t)<∞ is covariance stationary if (i) E(xt) is constant; (ii) Var(xt) is constant; and (iii) for any t,h≥1,Cov(xt,xt+h) depends only on h and not on t.
On a practical level, if we want to understand the relationship between two or more variables using regression analysis, we need to assume some sort of stability over time.
If we allow the relationship between two variables (say, yt and xt) to change arbitrarily in each time period, then we cannot hope to learn much about how a change in one variable affects the other variable if we only have access to a single time series realization.
In stating a multiple regression model for time series data, we are assuming a certain form of stationarity in that the βj do not change over time.
3.4.2 The MACD indicator
Moving Average Convergence Divergence (MACD) is a trend-following momentum indicator that shows the relationship between two moving averages of a security’s price. The MACD is calculated by subtracting the 26-period Exponential Moving Average (EMA) from the 12-period EMA.
The result of that calculation is the MACD line. A nine-day EMA of the MACD called the “signal line,” is then plotted with the MACD line, which can be a signal for buy and sell. Traders may buy the security when the MACD crosses above its signal line and sell - or short - the security when the MACD crosses below the signal line.
An exponential moving average (EMA) is a type of moving average (MA) that places a greater weight and significance on the most recent data points. The exponential moving average is also referred to as the exponentially weighted moving average. An exponentially weighted moving average reacts more significantly to recent price changes than a simple moving average (SMA), which applies an equal weight to all observations in the period.
In the next example, by default, the function MACD creates a 12 days EMA and 26-days EMA (Investopedia, 2023).